Cache All the Things

Infinite knowledge. Digital Art.
Context
An engineering manager that will remain unnamed told me his story of trying to find the solution to a technical problem on the internet.
It's the typical question -> google -> stack overflow -> answer pathway with a twist - when he finally found the answer, he realized that he himself had created the question a year prior.
I like this story because it's easy to relate to. Haven't we all searched for something that turned out to be a problem we've already encountered?
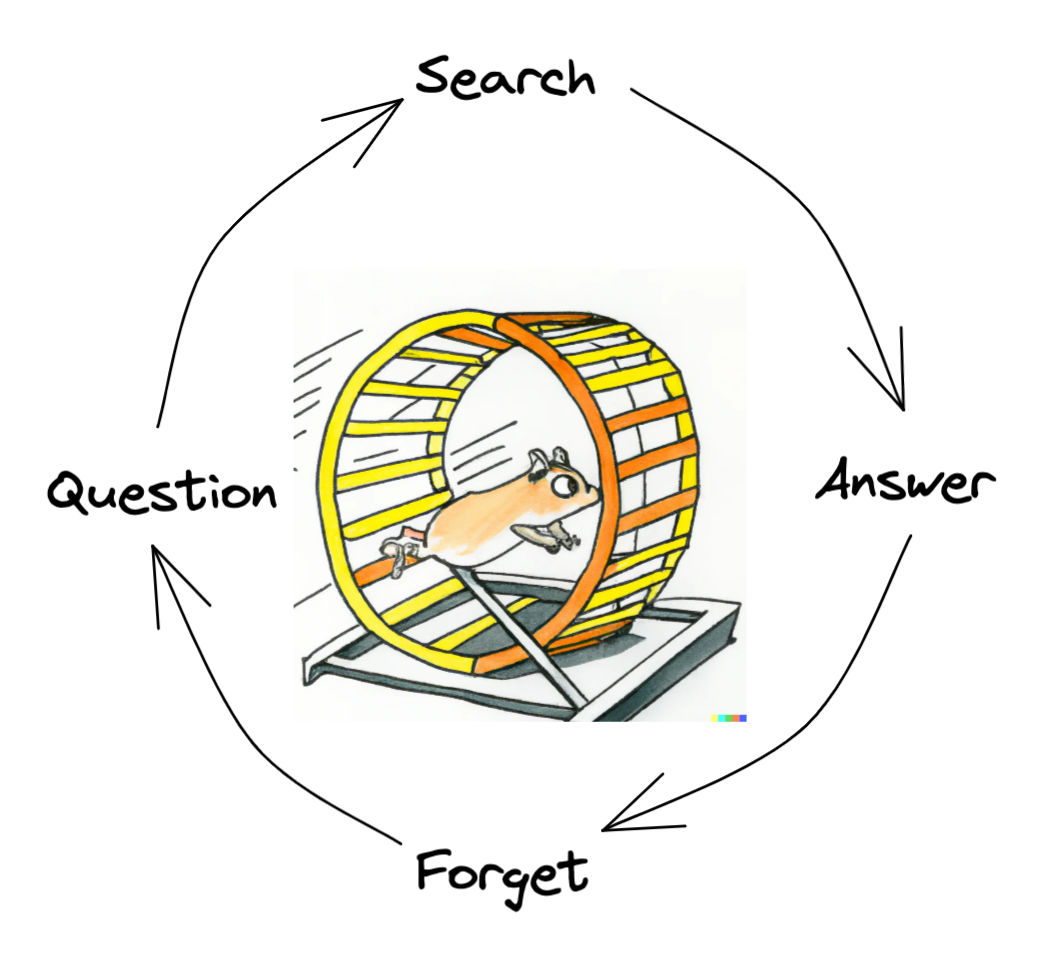
The process of searching for answers on the internet is what doing software (and much of knowledge work) is like in the 20th century.
There is an overwhelming amount of information we need to process just to do our job. It is impossible (nor useful) to keep this information in our heads so we rely on services like google to help look up what we don't know (or have forgotten).
While this can work, there is a problem when we come to depend on this workflow for getting through the day. It's like only relying on google maps to get home - while this works, you also lose the ability to navigate on your own in the process.
This is a groundhog day loop - regardless of how much you search, learnings are quickly forgotten and mastery is never built.
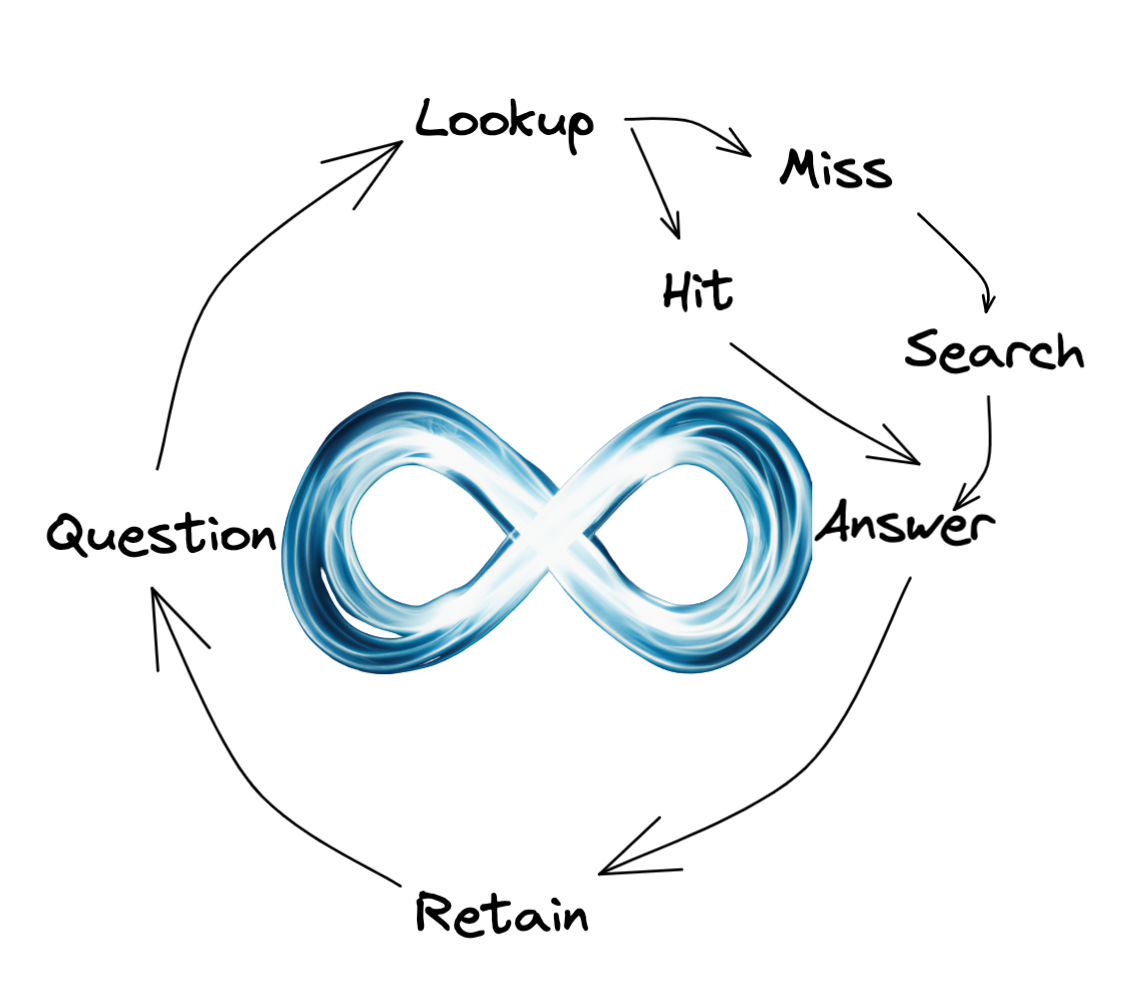
Now imagine the same workflow where instead of starting with a search, you look up information in your personal knowledge cache. This cache contains every problem you have ever encountered and is accessible in seconds. If you find the answer, you're done, and if not, you can be certain that it is not there. Only then do you fall back to search. When you find the answer, you add it to your cache so you can make use of it in the future.
This is a mastery loop - instead of losing your place on every question, you build and reinforce your understanding of things with each problem you encounter.
The key to building this particular mastery loop comes from combining the following PKM workflows:
- a modified version of the progressive summarization method
- A Hierarchy First Approach to Note Taking
Together, they let you cache all the things!
Progressive Summarization
If you're not familiar with the term, progressive summarization is the means of incrementally retaining insights from text to be used at a future date. It is built around five layers of summarization and pioneered by Tiago Forte, a big influencer in the PKM space.

The steps are described in more detail below:
- If you come across useful information, save excerpts from it. This is layer 1. The benefit: next time you revisit the notes, you can just go over your excerpts instead the entire text.
- If you happen to need the text again, bold specific passages that stand out as you're reviewing. This is layer 2 and serves to make future skimming easier.
- If you require the text again, ==highlight from the bolded parts== insights that are especially poignant. This is layer 3 and it represents the highest quality insights that you've derived from the specific text.
- If you still have need of the text, make a summary of it in your own words. This is layer 4 and represents the start of reframing the text in your own words.
- If you then find the text relevant in some current project, the final step is to remix it into your own material. This is layer 5 and represents the culmination of all the prior layers.
There are some highly desirable characteristics of progressive summarization:
- just in time vs ahead of time: you only do the work when you need to
- incremental work: you only do minimal work at each layer which can then be leveraged in later layers
- active vs passive: you actively read the text instead of skimming it
A Hierarchy First Approach to Knowledge Management
The Hierarchy First Approach to Knowledge Management excels at helping people organize lots of information in a consistent structured way for later retrieval.
It provides a foundation to create a knowledge base that can grow to any size while ensuring that information remains accessible. You can read more about the details of this workflow in the original blog post - It's Not You - It's Your Knowledge Base
Cache all the Things
Progressive Summarization helps with retaining key insights from text, the Hierarchy First Approach helps organize those summaries so that they can be found again later. The combination of the two lets us create a knowledge base of distilled insights that can be accessed at a moment's notice.
There are five levels to this hybrid technique and we'll spend some time explaining each in greater detail below.
- Note
- Expand
- Split
- Standardize
- Refactor
Level 1 - Note
When you come across information that turns out to be useful, make a note of it. This is done by copying the relevant excerpts from the source material.
Greg is a new engineer at Literal, a social VR company. Their first assignment is to change a hard-coded welcome string to an internationalized string. Their mentor recommends using the CLI tool
grepto find all instances of the string. Greg has never usedgrepbefore so spends some time learning about it. He captures a basic example of running the command in his notes.
Synopsis
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
Example
grep 'python' *
Level 2 - Expand
If you find yourself continuously going back to the source material because you end up using more functionality, invest in adding more information to your note. For example, this could detail instructions for the new functionality or hard-won insights you've discovered through trial and error.
Greg finishes his first assignment and ends up doing more localization work. He uses
grepquite a lot and discovers that he can use regex to speed up his workflow. He has also at this point noticed some mistakes he keeps making with the options. Greg makes a note of all of this.
Synopsis
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
Gotchas
- large repetitions can cause memory exhaustion
- must escape
()|-signs - set option flags before the PATTERN
Options
- -P use perl like regex (you can lookahead and lookbehind)
- -i: Ignore casecase
- -x: Force search to match line
Example
grep 'python' *
Level 3 - Split
If you continue to expand the note, the note will eventually exceed the limit of a single page (eg. 800 words). At this point, you want to split your notes into smaller notes
NOTE: The process of splitting of large notes into smaller notes is also known as the amoeba pattern
Greg finds himself using grep all the time and he now has to spend time scrolling through his
grepnote to find what he needs. He has a section on snippets that makes up most of the note so he decides to split it off into its own note.
.
└── grep
└── snippets
Level 4 - Standardize
As you continue the process of expanding and splitting notes, you tend to find certain clusters of notes will all have the same shape. When this pattern starts to emerge, you can standardize these patterns into hierarchies.
As Greg takes on bigger assignments, he also expands his arsenal of CLI commands. Greg realizes after a while that all CLI commands have a similar structure and so he consolidates it in a hierarchy.
.
└── cli/
├── grep
│ └── snippets
├── sed
├── awk
│ └── snippets
├── git
├── test
└── ...
Level 5 - Refactor
In software engineering, refactoring is "the process of restructuring existing (information) — changing the factoring — without changing its external behavior"
Refactoring is done because the original structure can outgrow its usefulness. Sometimes the underlying information changes or your understanding of it does. Regardless, this means that you will need to update your hierarchies to account for this change.
Greg is tasked with a new assignment that involves working with windows and the PowerShell instead of the Linux terminal. He discovers that the PowerShell has its own set of commands and that the same commands in Linux will have slightly different behavior for Powershell. Greg proceeds to refactor his original hierarchy
.
└── cli/
├── linux
│ ├── grep
│ │ └── snippets
│ ├── sed
│ ├── awk
│ │ └── snippets
│ ├── git
│ └── test
│ └── ...
└── powershell
├── CopyCmd
├── grep
└── ...
Challenges
The workflow we just described can be applied outside of CLI commands to cover any information you might want to track. It allows you to systematically build up both your reference of "facts" in a domain as well as an underlying mental model of said domain.
The challenge in actually implementing this workflow generally surfaces in the latter two levels: standardization and refactoring.
Standardization into hierarchies is difficult because creating hierarchies is usually time-consuming and adds friction to both the retrieval and capture of new information.
Refactoring is hard because it usually relies on manually moving old notes into new hierarchies and also breaks links in the process.
This is why we created Dendron - a note-taking tool that helps people organize and refactor their notes.
By making it easy to standardize into hierarchies and refactor as needed, Dendron makes it possible to create, maintain, and make use of knowledge bases that span from a single README file to hundreds of thousands of notes!
Conclusion
Information can be overwhelming but it doesn't have to be.
We've long passed the point where we can keep everything in our heads. While that information is available on the internet, it takes time to find and is hard to retain.
By combining Progressive Summarization with a Hierarchy First Approach to Knowledge Management, we've created a workflow that lets us externalize an unlimited amount of information and the means to quickly find it again when needed.
This incremental caching of everything represents an escape from the endless cycle of searching for things we've already done and instead, lets us focus our efforts on the novel and bigger challenges of the day.
Imagine how much more effective we could be, as individuals, teams, and as a society, if we could build on top of what we knew instead of spending time forgetting and re-discovering hard-earned knowledge?
And now stop imagining and start caching!
Enjoy the blog? Subscribe to our newsletter!
Newsletters not your thing? You can also follow us elsewhere on the interwebs:
- Join Dendron on Discord
- Register for Dendron Events on Luma
- Follow Dendron on Twitter
- Checkout Dendron on GitHub
Interested in creating your own knowledge base using markdown, git, and VSCode? Get started with Dendron today.